COMPETITIONS
Fine tune Clip model Vit-B-32 for specific datasets with few Few-shot (Jul 2024)
Contest:The 2024 Jittor Artificial Intelligence Challenge
Collaborator: Junjie Qiu. Jiahua Zhao
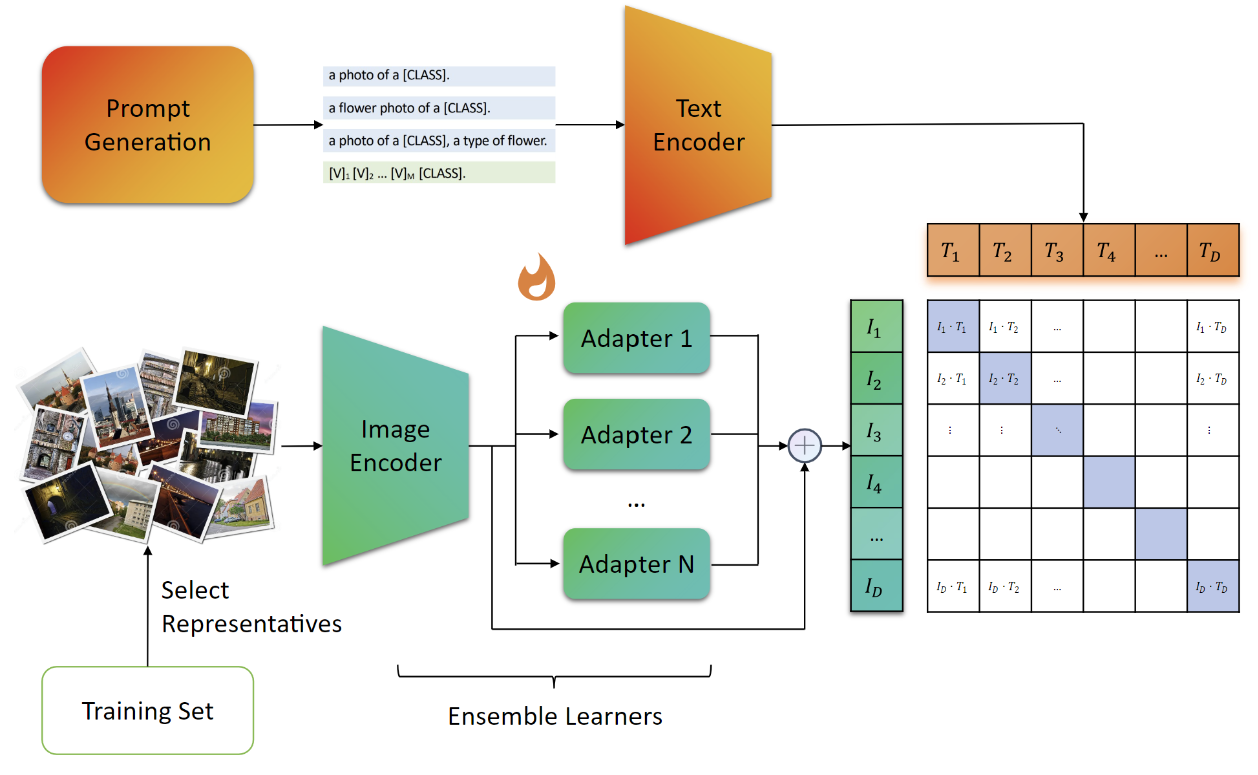
This project contains the implementation of the Niko Kawaii team's code for the 4th Jittor Challenge, Jittor - Open-Domain Few-Shot Visual Classification Competition. The technical features of this project are as follows:
- Boosting: We drew inspiration from the Boosting method in traditional machine learning and proposed an ensemble learning approach based on vision-language models. By sharing the Text Encoder and Image Encoder, we alternately trained multiple Adapters and fused the outputs of the Adapters, effectively reducing the bias and variance during CLIP inference.
- Clustering-based Image Selection: We proposed a clustering-based image selection method. By clustering images, we were able to select representative images for model training, thereby reducing the impact of noisy data on the model and improving training effectiveness.
- Prompt Engineering: We referred to the output of several models and made manual adjustments. Through prompt engineering, we achieved better caption representation.
We also designed three types of Adapters, including conv, mlp, and attn. Our experimental results indicate that the conv type Adapter performed best in most cases. We believe that future research can further explore the design and training methods of Adapters to enhance model performance.
We improved the accuracy of the model from approximately 62% to 69.15%, which is ranked 35th in the competition.
No report is avaliable for this project. Github page: https://github.com/haroqiu/jittor-Niko-Kawaii-Boosted-CLIP
Momemtum: is it truly exist in tennis game? (Feb 2024)
Contest: COMAP-MCM-C 2024
Collaborator: Yupeng Su. Xiaoqun Liu

In the realm of sports, the concept of "momentum" is widely discussed among athletes and fans alike. It's often described as a player's perceived streak of success or failure, seemingly independent of their inherent skill level. For instance, a tennis player might experience a strong performance one week but struggle the next, with factors like weather, mood, or external conditions being blamed for the variance.
Our paper delves into the elusive nature of momentum in sports, particularly in tennis. We aim to investigate its existence, how it transitions between players, and its impact on game outcomes. Leveraging the Wimbledon 2023 match data provided by COMAP, our model employs Logistic Regression with adjusted inputs, utilizes NMS to figure out the change of momentum, and implements the Anderson-Darling test to compare the observed momentum effects to those simulated under random conditions.
Our report is avaliable here.
Predicting Wordle Result Based on Random Forest (Feb 2023)
Contest: COMAP-MCM-C 2023
Collaborator: Yupeng Su. Xiaoqun Liu

Wordle is a word guessing game that appears on the back of the New York Times newspaper and also has an online version for people to enjoy. The words are all five letters long, and players have a limited number of guesses. Each correct guess returns information on whether the guessed word is in the target word and if so, its correct position. Some players share their results on Twitter. COMAP collected data from players who shared their results on Twitter in 2022 (number of guesses and whether they guessed the word). Based on this data, we need to predict the daily number of players for the company (using an ARIMA model), determine the distribution of the number of attempts for any given word (using Random Forests), and further assess the difficulty of guessing a particular word (using K-means clustering). Finally, we propose strategies for improving game quality for Wordle based on this analysis. Additionally, using the Monte Carlo algorithm, we've designed a word guessing machine that maximizes the probability of guessing the word(Wordle’s word dataset is scraped online). This machine indicates that the number of attempts people actually need to guess the word is much higher than the number of attempts shared on Twitter.
Our report is avaliable here.
CLASS PROJECTS
Kleinberg's small world phenomenon: A modification (Jun 2024)
STA5001: Frontiers in Statistics
Collaborator: None
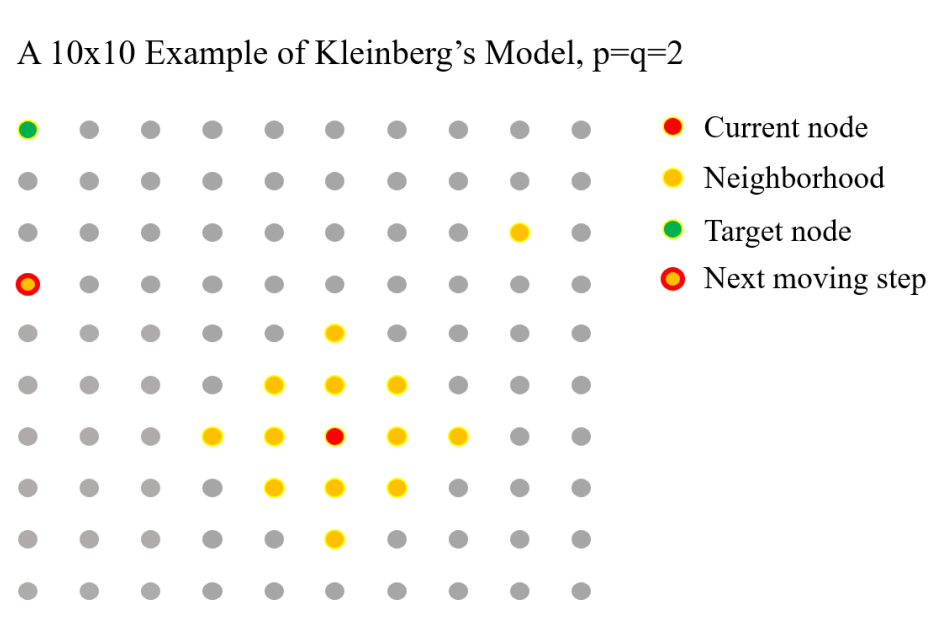
The network of relationships between people is a fascinating subject. How many friends of my friends are connected to Bill Gates? Back in the 1960s, renowned American social psychologist Stanley Milgram conducted a famous letter-passing experiment, which led to the well-known Six Degrees of Separation theory and the small world phenomenon. The rise of the internet further spurred a wave of research into social networks. In 2000, Jon Kleinberg proposed a mathematical model for social networks. For this project, I have made some modifications to the long-range connections in Kleinberg's model to explore how changes in assumptions can affect the network. Specifically, I investigate which power-law distribution can optimize the network under the modified conditions.
Our report is available here. Github page: https://github.com/Heqijia/STA5001
A Company Classifyier and Stock Recommendation System based on company's financial data (May 2024)
MA304: Multivariate Statistical Analysis
Collaborators: Ruiwei Liang, Yuru Feng, Xinyi Zhu
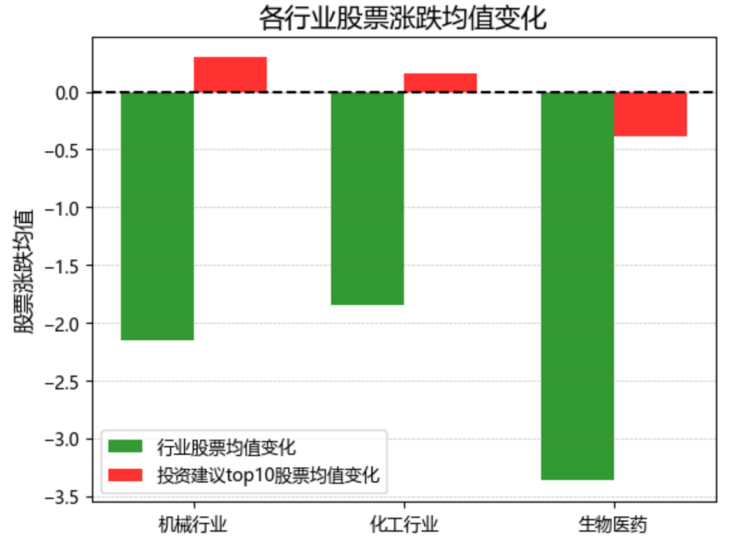
The fluctuations of financial markets are always thrilling. Analyzing a company's performance and predicting stock trends have long been the tasks of banks and investment analysts. In this project, we analyzed companies' positions and operating conditions within their respective industries based on their specific financial statements. We also made rough predictions about stock price movements to provide investment recommendations for investors within specific sectors. Our data was sourced from baostock.com, focusing on the financial statements of companies for the fourth quarter of 2023. After categorizing and rating the companies, we offered stock-picking advice for the industries. Among the three industries we analyzed (machinery, chemical, and biomedical), our recommended investment portfolios significantly outperformed the average stock price fluctuations in these sectors, using the opening prices on April 1, 2024, as a reference.
Our report is avaliable here. Github page: https://github.com/Heqijia/MA304-proj
Shenzhen metro's operation schedule optimization (May 2024)
STA 326: Data Science Practice
Collaborators: Cheng Guo, Jiachen Zhou, Lingmin Yan, Lu Wang
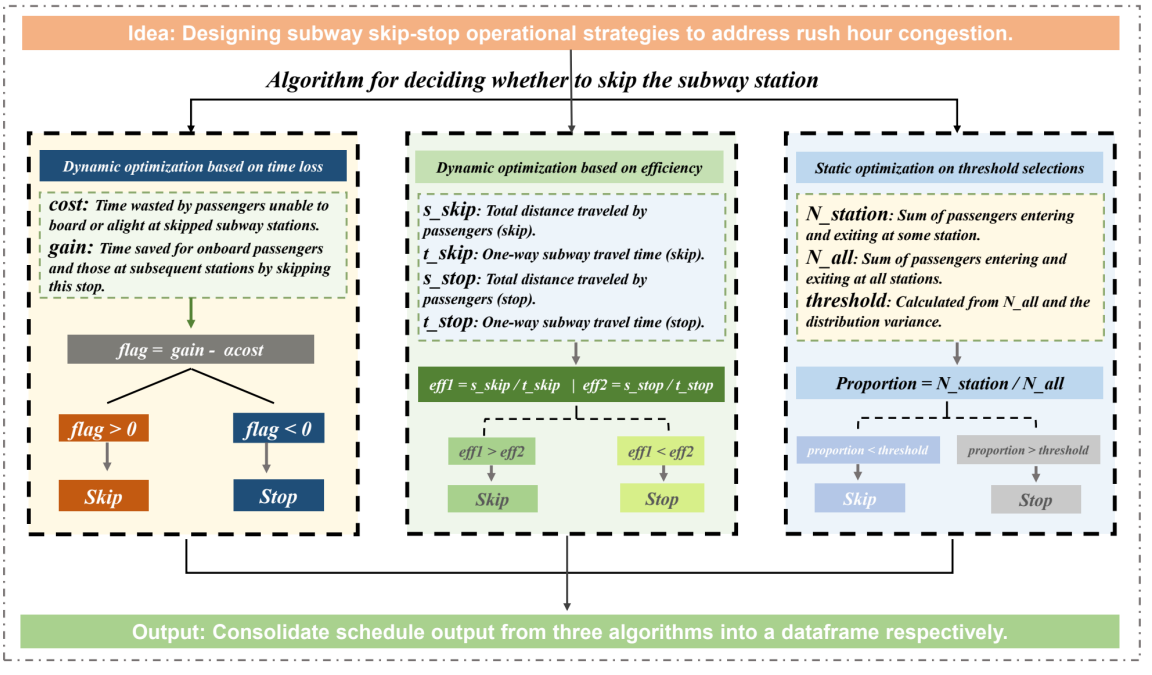
Taking the subway is always frustrating; the constant opening and closing of doors and the frequent stops and starts of the train waste a lot of commuters' time. Improving commuting efficiency with existing resources is a significant aspect of building smart cities. Based on the passenger flow data of Shenzhen Metro Line 5 on August 31, 2018, and without considering the regularity of station stops, we optimized the train stops during the morning peak. In this project, we designed three different greedy algorithms and further optimized them with local search. We found that during peak congestion periods, adopting a flexible skipping-stop strategy can save passengers 10% to 15% of their average commuting time.
Click these 2 links to see our improvements on metro data: 1. Station Passenger Flow, 2. Metro Schedule.
Our report is avaliable here. Github page: https://github.com/Heqijia/STA326-Project
A visualization & Interaction dashboard of U.S.'s used car transaction data (Dec 2023)
CSE 332: Introduction to Visualization
Collaborator: None
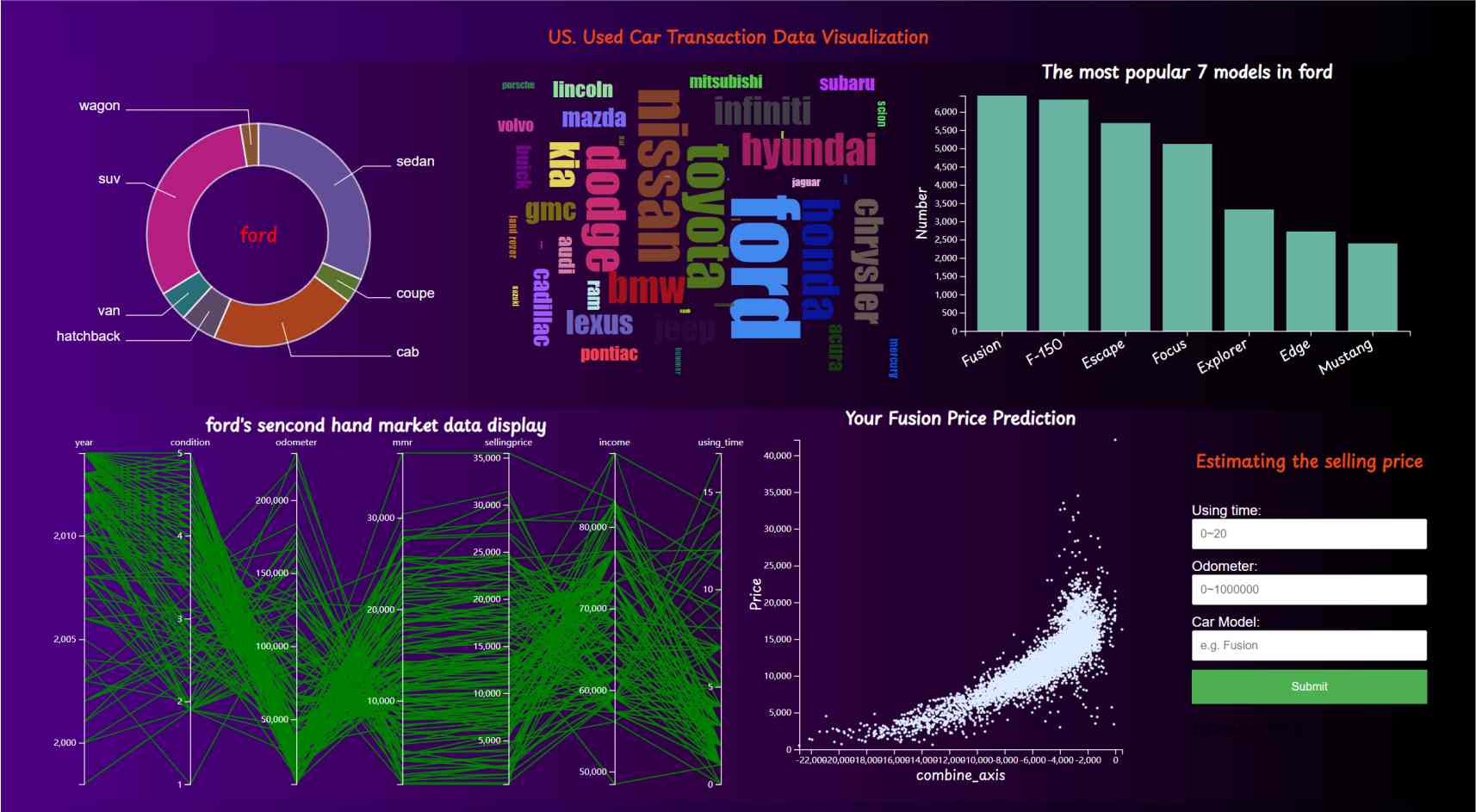
This is a visualization dashboard built with D3 to display transaction data in the US secondhand car market. The dataset, containing about 500,000 transactions, was directly downloaded from Kaggle. The dashboard includes several components:
- A pie chart showing the distribution of car types for a selected brand.
- A word cloud presenting the brands and their proportions in the secondhand market.
- A bar chart showing the top 7 best-selling cars of the selected brand.
- A parallel coordinate display detailing the specifications of the cars.
- A prediction model that estimates a car's price based on its model, year, and odometer. The result is returned and displayed on the scatter plot. This prediction model is simply implemented using KNN.
Click here to play the dashboard!
Our report is avaliable here. Github page: https://github.com/Heqijia/CSE332_lab5
A face detection system based on DeepFace (Jun 2023)
CS 308: Computer Vision
Collaborators: Qiang Hu, Bin Huang
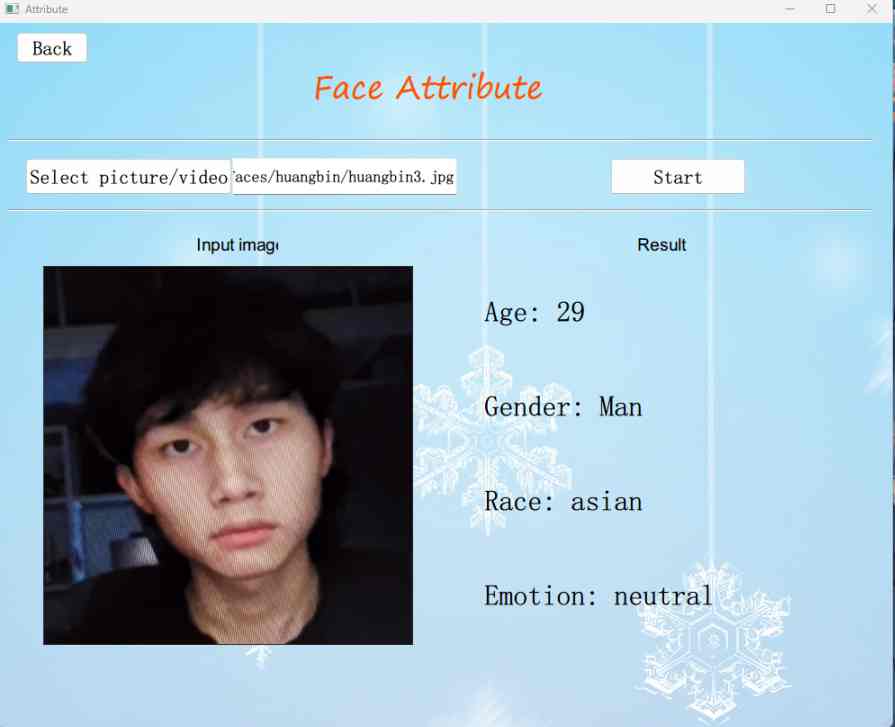

The face recognition algorithm has been continuously refined and widely applied in contemporary society. In this course project, we encapsulated the Deepface model and created a user interface for a face recognition system using Python's PyQt5. and did performance analysis based on our own dataset. The system comprises five main functions:
- Face attribute analysis: Input an image and get predictions for age, ethnicity, gender, and emotion.
- Video Face detector: Detect and track faces in a video input.
- Image Face detector: Detect faces in a still image.
- Find matching Faces: Built a local face database comprising photos of three project members and various online personalities. Compare newly input images with the database and return whether they match any database photos and who they might be.
- Face Verification: Input two photos separately and determine whether the faces in the photos belong to the same person.
For more details, you can view our report or github Repository:
Our report is avaliable here. Github page: https://github.com/Fae42/cv-final-project
Bilibili User Study Data Analysis (Dec 2022)
STA217: Introduction to Data Science
Collaborators: Ruiwei Liang, Leping Li

Bilibili has gradually matured over the past few years in China (similar to YouTube), becoming a highly concentrated cultural community and video platform for the younger generation in China. As the number of Bilibili users and vloggers has increased, Bilibili has come to reflect the value orientations of China's younger generation to some extent. Consequently, the importance of big data research on Bilibili has become increasingly evident.
By analyzing the behavior of Bilibili's vloggers, we can gain a clearer understanding of the psychological needs and interests of today's youth, as well as the relationship between certain behaviors of vloggers and their number of fans. This allows us to better grasp the current mainstream values and provide relevant suggestions for both new and experienced vloggers on creating videos and attracting fans.
Dataset:
- A CSV file containing basic information of 5k vloggers in 2019, from Prof. Yifang Ma
- A tracking data based on the ID of the vloggers (2022), collected by Google Web Scraper
Our report is avaliable here. (In Chinese)
Number Puzzle Game Solver (Dec 2022)
CS203B: Data Structures and Algorithm Analysis
Collaborator: Junjie Qiu
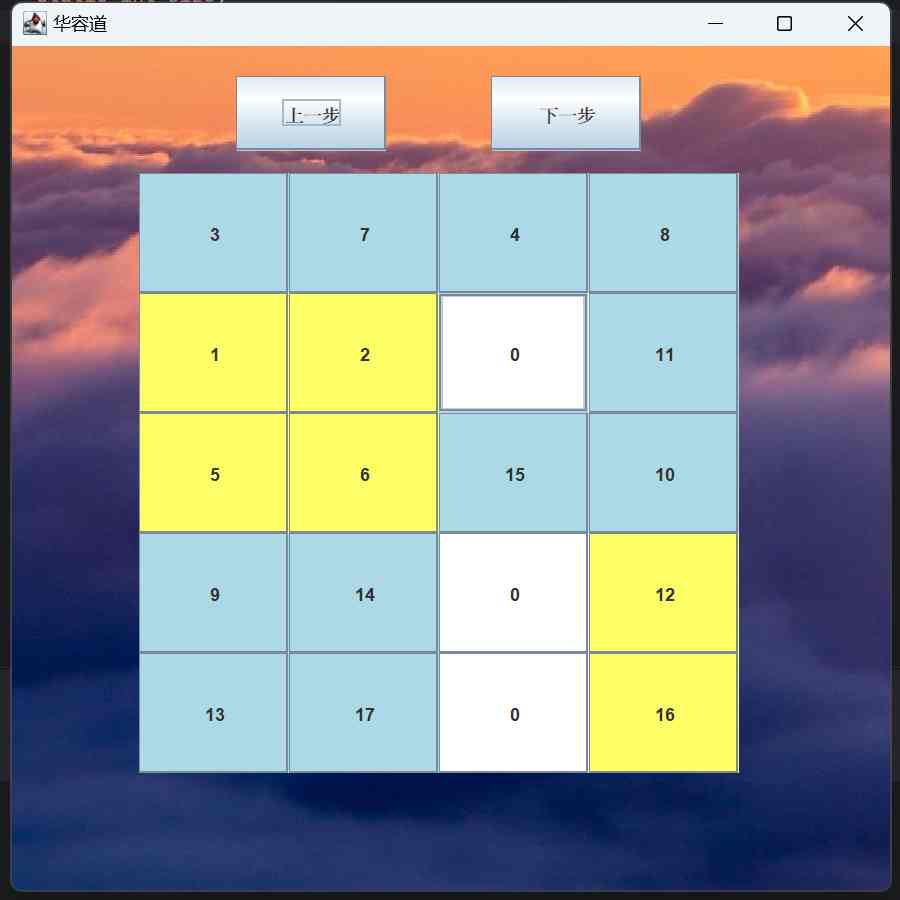
This project aims to develop a solver for a number puzzle game. Given any initial configuration, the goal is to determine if there is a solution. In this puzzle, 0 represents an empty space, yellow blocks represent large blocks (which can be 2x1, 1x2, or 2x2), and blue blocks represent small blocks (which are 1x1). For example, the final solution should look like [[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], [13, 14, 15, 16], [17, 18, 0, 0]]. In the searching process, only the blocks adjacent to the 0 block can be moved.
We implemented three solvers: Solver, Solver1, and Solver2. The Solver uses a self-designed greedy algorithm, Solver1 uses pure BFS (Breadth-First Search), and Solver2 uses pure DFS (Depth-First Search). The greedy algorithm in Solver prioritizes the move of blocks based on the distance between their current dashboard structure and the target dashboard structure, giving higher priority to the move of blocks and structures that will lead the board closer to its final structure. A Min Priority Queue (MinPQ) is used to manage the board's search structure. When the size of MinPQ exceeds 500,000, we retain only the best 10,000 points. This implementation performs significantly better than Solver1 and Solver2, allowing Solver to handle boards as large as 6x6 in a limited amount of time, while the other two can only handle up to 3x3 boards. For detailed information on the algorithms, please refer to [...] (Written in Chinese)
Once the search process is complete, a final dashboard will be generated, displaying the steps taken to arrive at the solution.
Our report is avaliable here. Github page: https://github.com/Heqijia/DSBB-project
An interview: XiaoYang WANG: Working as a coral reef conservationist (Dec 2022)
HUM073: Nature, Wilderness and Civilization
Collaborators: Nov BunnareakSathya, Yuqing Zhao, Ruiyao Chen, Yiyang Xia

Xiaoyang Wang is a member of the Shenzhen Dive4love club, a newly minted diving instructor, coral reef conservationist and educator on the Dapeng Peninsula, Shenzhen. Despite being a latecomer to this field, Wang has an immense passion for nature. In this interview, we mainly discussed why Wang chose diving and coral conservation as his career, the current state and challenges of coral reef conservation, people's understanding and awareness of nature conservation, the role of education, and the social conflicts between environmental protection and development. The detail content can be seen in this report.
Our report is avaliable here.
Chess Game System (May 2022)
CS102 A: Introduction to Computer Programming
Collaborator: Jingying Gu
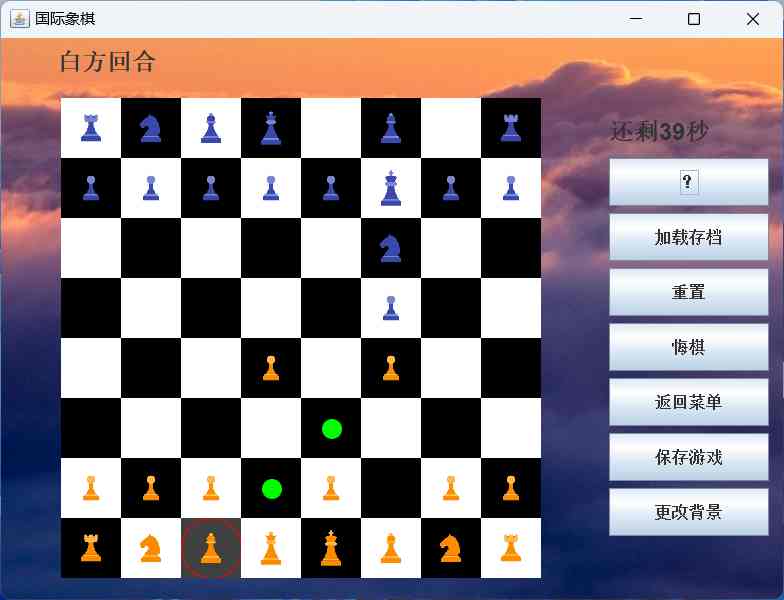
In this project, a chess game system is developed using Java (the interface is in Chinese). All rules of chess are implemented in this system. The interface is created using javax.swing. Click hello.exe to start the game! Some supplementary functions include:
- Hint for the next move, displayed as green dots.
- Countdown: each player has 45 seconds to make a decision; otherwise, the turn automatically switches to the opponent.
- Music and various background settings.
- Game saving: this feature generates a text file containing the basic information of the chessboard, including whose turn it is.
- Undo a move: multiple undos are allowed.
No report is abaliable for this project. Github page: https://github.com/Heqijia/IntroCP-Project